K-Nearest Neighbors (KNN)
Tất cả các thuật toán từ đầu các phần trước đều đi theo 1 mô típ. Dùng training data để huấn luyện mô hình tìm ra 1 công thức tạo ra một đường phân cách để dự đoán class cho các điểm dữ liệu mới. Nhưng thuật toán này đi theo 1 hướng khác, chúng ta sẽ không có quá trình huấn luyện. Thay vào đó các data point của bộ data được sử dụng trực tiếp khi ta đem mô hình đi dự đoán các giá trị mới.
Để sử dụng thuật toán này, ta cần phải:
- Tìm xem
kbằng bao nhiêu (thường sẽ chọn số lẻ như 3, 5). - Tìm
kđiểm dữ liệu gần với dữ liệu mới nhất. - Tìm xem trong
kđiểm dữ liệu, đa số chúng thuộc class nào thì sẽ gán điểm dữ liệu mới cho class đó.
Chọn k phù hợp rất quan trọng, k quá bé sẽ bị overfitting, k lớn quá sẽ bị underfitting.
Ưu điểm là dễ hiểu, trực quan, dễ giải thích kết quả. Nhược điểm sẽ vô cùng chậm với bộ dữ liệu lớn có rất nhiều data point.
Ensemble Learning
Đây là cách kết hợp các mô hình có độ chính xác thấp thành mô hình có độ chính xác cao. Áp dụng 1 nhận định được thừa nhận rộng rãi là kết hợp nhiều mô hình lại với nhau sẽ tốt hơn là sử dụng các mô hình đơn lẻ.
Ta có 4 kiểu chính: Bagging, Boosting, Voting, Stacking.
1. Bagging
Ví dụ trực quan nhất là về Random Forest.
Mục tiêu là huấn luyện nhiều mô hình con có cùng loại với nhau. Chúng được gọi là Week Models. Mỗi model con sẽ được huấn luyện dựa trên bộ data khác nhau được lấy mẫu qua bộ data gốc thông qua Boostrapping (lấy mẫu có hoàn lại).
Các mô hình con bị overfitting (low bias + high variance) là điều bình thường.
Bagging nâng cao độ chính xác của mô hình bằng cách giảm variance.
2. Boosting
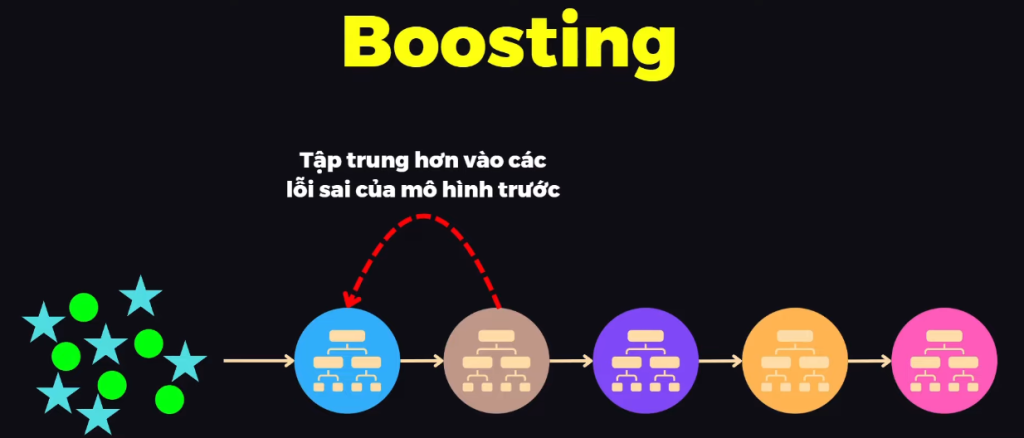
Kết hợp các mô hình con 1 cách tuần tự. Các mô hình con đều được huấn luyện trên toàn bộ tập dữ liệu. Mô hình 1 sẽ được huấn luyện với toàn bộ data và đưa kết quả. Mô hình 2 sẽ được huấn luyện với toàn bộ data và tập trung hơn vào những dữ đoán sai của mô hình 1. Áp dụng tuần tự với các mô hình sau.
Để mô hình sau tập trung hơn vào điểm dữ liệu mà mô hình trước dự đoán sai, ta sẽ gán trọng số cao hơn cho điểm dữ liệu sai và trọng số thấp hơn cho điểm dữ liệu đúng.
Với bài toán regression, thay vì tính averaging không trọng số (mô hình con bình đẳng trong đóng góp đưa ra dự đoán), còn ở đây là trung bình có trọng số, mỗi mô hình con khác nhau có tầm quan trọng khác nhau. Các mô hình con đầu tiên có trọng số thấp hơn các mô hình con phía sau.
Boosting nâng cao độ chính xác của mô hình bằng cách giảm bias.
Ngoài Scikit-learning, có hẳn 1 thư viện riêng là XGBoost để thực hiện thuật toán này.
3. Voting
Kết hợp nhiều mô hình con 1 cách song song, các mô hình con sẽ thuộc về các loại khác nhau (1 con là SVM, 1 con là KNN). Các mô hình con đều được huấn luyện trên tập dữ liệu gốc thay vì chia nhỏ.
Có 2 loại:
- Hard voting: Đưa dự đoán cụ thể là class nào.
- Soft voting: Không đưa dự đoán cụ thể mà đưa ra xác suất.
4. Stacking
Huấn luyện nhiều mô hình và được chia làm 2 nhóm:
- Base model: thuộc nhiều loại khác nhau.
- Meta model: gồm 1 model duy nhất.
Đầu tiên, ta chia dữ liệu thành bộ train và bộ validation. Sau đó, huấn luyện base mode với bộ train, sau đó đem dự đoán với validation. Các dự đoán của base model trên validation được dùng làm input huấn luyện meta model. Với các input này meta model sẽ học cách kết hợp dự đoán của các base model để đưa ra kết quả cuối cùng.
Meta model không nhất thiết là model phức tạp mà có thể là các model rất đơn giản.
Tổng hợp lại, Enssemble Learning có nhược điểm:
- Chậm do phải huấn luyện nhiều model.
- Có độ giải thích rất là thấp.
Tất cả các thuật toán trước giờ đều là Supervised (học có giám sát). Bây giờ, hãy tìm hiểu các thuật toán Unsupervised (học không có giám sát).
K-means Clustering
Mục tiêu là phân các điểm dữ liệu thành các cụm khác nhau sao cho các điểm dữ liệu trong cùng 1 cụm sẽ tương đồng nhau. Dữ liệu cụm này sẽ khác biệt nhiều với dữ liệu của cụm khác.
Thuật toán này có ưu điểm là dễ hiểu, dễ sử dụng và dễ trực quan hóa. Nhược điểm là:
- Chọn
ktối ưu không hề dễ chút nào. - Nếu các điểm trung tâm của các cụm dữ liệu được khởi tạo không tốt sẽ dẫn đến kết quả tồi hoặc hội tụ rất chậm.
Principle Component Analysis (PCA)
Thuật toán này rất hay được sử dụng khi ta cần trực quan hóa dữ liệu N chiều về 2D hoặc 3D.
Ý tưởng của PCA là biến đổi dữ liệu từ chiều không gian gốc ban đầu sang chiều không gian mới sao cho ở trong chiều không gian mới này thì độ phân tán của dữ liệu là tối đa theo các trục. Sau đó ta sẽ sắp xếp các trục theo thứ tự giảm dần của độ phân tán dữ liệu. Sau đó ta sẽ chọn và giữ lại k trục có độ phân tán của dữ liệu là lớn nhất.